We have one database server that is running on an old version of Aurora based on MySQL 5.6. AWS is deprecating that version soon and it needs to be upgraded, so I have been working on replacing it. Upgrading the existing 5.6 server to 5.7, then to 8.0 isn’t an option due to an impossibly huge InnoDB transaction history list that will never fix itself. Plus, I want to improve a couple of other things along the way.
I made several attempts and migrating from Aurora 5.6 to Aurora 8.0, but during that process, I grew tired of Aurora quirks and costs. Here are some of my raw notes on what was an embarrassingly long migration of a database server from Aurora to MySQL. Going from MySQL to Aurora took just a couple of clicks. But converting from Aurora back to MySQL took months and a lot of headaches.
TLDR: Along the way, I tried Using Amazon’s Database Migration Service, but eventually gave up for a good old closely monitored mysqldump and custom scripts.
I had a few goals/requirements:
- Get rid of or soon-to-be-deprecated Aurora instance based on MySQL 5.6
- Stop Paying for Storage IOPS (often over $100/day)
- Convert tables from utf8mb3 to utf8mb4
- Minimal downtime or customer disruption. Some disruption during low-usage times is okay.
A new MySQL 8 instance with a GP3 storage volume and the recently announced RDS Optimized Writes means that MySQL should be able to handle the workload with no problem, and gets this server back into the MySQL realm, where all of our other servers are, and with which we are more comfortable.
Attempts at using AWS Database Migration Service (DMS)
This service looked promising, but has a learning curve. I eventually gave up using it because of repeated problems that would have taken too much effort to try and resolve.
First attempts:
On the surface, it seems like you configure a source, configure a destination, and then tell DMS to sync one to the other and keep them in sync. It does this in two Phases: the Full Dump, and the Change Data Capture (CDC). I learned the hard way that the Full Dump doesn’t include any indexes on the tables! This is done to make it as fast as possible. The second, CDC Phase, just executes statements from the binary log, so without indexes on a 400+G table, they take forever and this will never work.
I also concluded that one of our 300+GB tables can actually be done in a separate process, after the rest of the data is loaded. It contains historic information that will make some things in the application look incomplete until it is loaded, but the application will work with it empty.
Second attempts:
Used DMS for the full dump, the configured it to stop after the full dump, before starting the CDC Process. While it is stopped, I added the database indexes and foreign keys. I tried this several times with varying degrees of success and trying to minimize the amount of time that it took to add the indexes. Some tables were done instantly, some took a couple hours, and some were 12+ hours. At one point I had figured it would take about 62 hours to add the indexes. I think I got that down to 39 hours by increasing the IOPS, running some ALTER TABLES in parallel, etc.
After indexes were added, I started the second phase of DMS – the Change Data Capture is supposed to pick up in time where the Full Dump was taken, and then apply all of the changes from the Binary Logs to the new server. That process didn’t go smoothly. Again, the first attempts looked promising, but then the binary logs on the server were deleted, so it couldn’t continue. I increased the number of days that binary logs were kept, and made more attempts, but they had problems with foreign key and unique constraints on tables.
The biggest problem with these attempts was that it took about 24 hours for the data migration, and about 48 hours to add indexes. So each attempt was several days effort.
Third and last attempts at using DMS:
After getting pretty familiar DMS, I ended up creating the schema via `mysqldump –no-data` then manually editing the file to exclude indexes on some of the biggest tables that would cause the import to go slow. I excluded the one large, historic table. My overall process looked like this:
- code>mysqldump –defaults-group-suffix=dumpschema –no-data thedatabase |sed “s/utf8 /utf8mb4 /” | sed “s/utf8_/utf8mb4_/” > /tmp/schema-limited-indexes.sql
-
- Edit /tmp/schema-limited-indexes.sql and remove foreign keys and indexes on large tables
- cat /tmp/schema-limited-indexes.sql | mysql –defaults-group-suffix=newserver thedatabase
-
- On the new server, run
ALTER TABLE the_historic_table ENGINE=blackhole;
- Start DMS process, make sure to have it stop between Full Load and CDC.
-
- Wait ~24+ hours for Full load to complete
- Add Indexes back that were removed from the schema. I had a list of ALTER TABLE statements to run, with an estimate time that each should take. That was estimated at 39 hours
- Start second Phase (CDC) of the DMS Task
- Wait for CDC to complete (time estimate unknown. The faster the above steps worked, the less it had to replay)
Unfortunately, a couple of attempts at this had the CDC phase still fail with Foreign key constraints. I tried several times and don’t know why this happened. Finding the offending rows took many hours since the queries didn’t have indexes and had to do full table scans. In some cases, there were just a few, to a few-dozen rows that existed in one table without the corresponding row in the foreign table. Its as if the binary log position taken when the snapshot was started was off by a few seconds and the dumps of different tables were started at slightly different positions.
After several attempts (taking a couple weeks), I finally gave up on the DMS approach.
Using MySQL Dump
Using mysqldump to move data from one database server to another is a process I have done thousands of times and written many scripts around. It is pretty well understood and predictable. I did a few trial runs to put together this process:
Temporarily Stop all processes on the master server
- Stop all background processes that write to the server
- Change the password so that no processes can write to the master
- Execute
SHOW BINARY LOGS on master and note the last binary log file and position. Do this a few times to make sure that it does not change. (Note that this would be easier if RDS allowed FLUSH TABLES WITH READ LOCK, but since it doesn’t, this process should work.
Dump the schema to the new server
This has the sed commands in the middle to convert the old “utf8” colations to the desired “utf8mb4” versions. When dumping 1TB+ of data, I found it helped performance a bit to do the schema changes with the sed commands first. That way the bulk of the data doesn’t have to go through these two commands.
Move the data
To move the data, I ran this command. Note that it starts with time so that I could see how long it takes. Also, it includes
time mysqldump --defaults-group-suffix=dumpdata --no-create-info thedatabase | pv |mysql thedatabase
My .my.cnf contains this section for the import
host=thehostname.cluster-czizrrfoedlm.us-east-1.rds.amazonaws.com
port=3306
user=dumper
password=thepassword
ssl-cipher=AES256-SHA:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA
quick
ignore-table=thedatabase.the_big_table
compression-algorithms=zlib
set-gtid-purged=OFF
max_allowed_packet=1024M
single-transaction=TRUE
column_statistics=0
net_buffer_length=256k
Note that the above command includes the linux pv in between which is a nice way to monitor the progress. It displays a simple line to stderr that allows you to see the total transfer size, elapsed time, and current speed.
266.5GiB 57:16:47 [ 100KiB/s] [ <=> ]
I experimented with several values for the NET_BUFFER_LENGTH parameter by dumping the same multi-GB table over and over with different values for NET_BUFFER_LENGTH. The size of this value determines how many values are included in the INSERT INTO statement generated by mysqldump. I was hoping that a larger value would improve performance, but I found that larger values slowed down. I found the best value was to use 256k.
NET_BUFFER_LENGTH value |
Elapsed Time |
| 64k |
13m 44s |
| 256k |
8m 27s |
| 256k |
7m 20s |
| 1M |
10m 23s |
| 16M |
11m 32s |
After Migration is Started
After the mysqldump has been started, I re-enabled traffic back to the master server by setting the password back to the original. I kept all background jobs disabled to minimize the amount of data that had to be copied over afterwards.
Final attempt to use DMS
After the mysqldump was finished, I attempted to use the DMS Change Data Capture process to copy over the data that had changed on the master. You can start a Database Migration Task that begins at a specific point in the Master Log position. Maybe. I tried, it, but it failed pretty quickly with a duplicate key constraint. I gave up on DMS and figured I would just move over any data needed manually via custom scripts.
Other findings
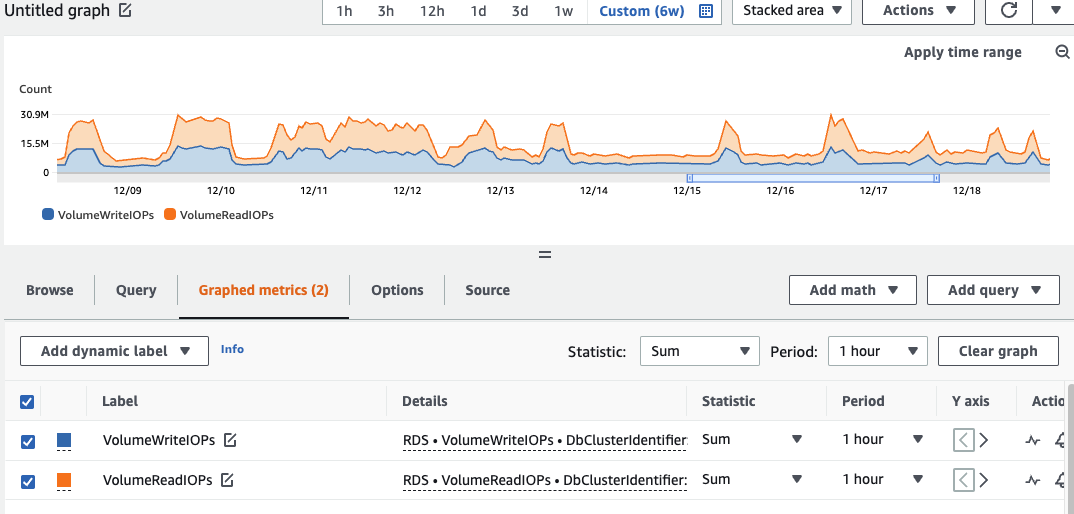
In attempting to maximimize the speed of the transfer, I attempted to increase the IOPS on the GP3 volume from its base level of 12,000 to 32,000. Initially that helped, but for some reason I still don’t understand, the throughput was then limited very strictly to 6,000 IOPS. As seen in the chart below, it bursted above that for some short parts, but it was pretty strictly constrained for most of the time. I think this has to do with how RDS uses multiple volumes to store the data. I suspect that each volume has 6,000 capacity, and all of my data was going to a single volume.

RDS IOPS Maxed at 6,000
That concludes the notes that I wanted to take. Hopefully somebody else finds these learnings or settings useful. If this has been helpful, or if you have any comments on some of the problems that I experienced, please let me know in the comments below.