5+ years ago one of my companies launched a product that is effectively a search engine monitoring tool. Is saves a lot of information about search engine results and the destination pages, then allows the users to see for which search phrases each pages ranks.
The workload is heavily write intensive. No matter the number of users we have to perform a bunch of data collection and save that into our database. A large increase in the number of users would increase the amount of reads, but the base workload of collecting all of the results remains the dominant workload for the database server.
We built this originally using MySQL 5.6, which we had used and managed extensively. We began having concerns with write capacity about the time the that AWS was starting to push Aurora as an alternative to MySQL, with cost and performance benefits. It seemed like an easy win, so we clicked the couple buttons and within minutes our database server was converted from MySQL to Aurora.
Things worked well for a long time. The product worked well and customers liked it. We tweaked the application here and there, but most of the base functionality just continued to do its thing. We moved on to developing other products and maintaining this one.
Fast forward a few years and we found that minor complaints had started to pile up. We add some indexes, make some code and queries more efficient. Adding indexes or altering a 500Gb table has some challenges, but there are tools like pt-online-schema-change that make table changes a little easier without downtime.
As time went on, we got better about allocating costs to the each product that we run and I did start to notice that the cost to run the Aurora instance was quite high. The instance cost itself was predictable, but the pricing of Aurora Database Storage includes a seemingly small cost of $0.20 per million I/O requests that was adding up to sometimes $200+ per day! It was at this point that I started to call Aurora a “Pay for Performance” product. Because it had the ability to scale I/O capacity quite high, inefficient queries executed fast enough not to notice. You just get charged more for them! It can be difficult to track down inefficient queries when everything is running fast. Performance Insights was very helpful to track down queries that could be optimized. By adding some indexes, we reduced our Database I/O and got our I/O costs down to under $100/day. On a traditional MySQL instance, with more limited I/O Capacity, these queries would have been more obvious, as they would have executed more slowly and our traditional troubleshooting would have brought them to our attention for the same optimizations. The “pay for performance” aspect of Aurora kept us from fixing the inefficient queries because they were hidden by being charged more.
Comparing Aurora Billed IO’s to MySQL IOPS
In November 2022 AWS announced that GP3 volumes are now available for RDS instances. The public documentation mentions a 3,000 IPS base capacity but doesn’t mention that for 400G+ volumes, that AWS actually spreads your storage over four volumes for theoretical base 12,000 IOPS. For an additional $0.02/IOPS you can increase your capacity up to 64,000 IOPS. So on the high end, the extra 52,000 extra IOPS at $0.02 comes to $1,040/month or about $35/day. There may be additional throughput needed as well, but for our workload, I found that IOPS was the bottleneck more than throughput.
Since we were still paying $60-$100 most days for Aurora Storage IOPS, it makes sense cost-wise to switch back from Aurora to MySQL. I also favor MySQL because it’s what we’re already used to. I’ve always thought that the monitoring and metrics available on Aurora instances wasn’t up to par with the MySQL instances. And there is just enough of a “black box” in Aurora that it makes things difficult.
In trying to estimate how much IOPS we needed if we switch back to MySQL, I found it a bit of work to estimate how much Aurora was using in terms that I’m used to seeing for MySQL. The only IO metrics available are “[Billed] Volume Read IOPS” and “[Billed] Volume Write IOPS”. These are under the “Cluster” in Cloudwatch Metrics and look like they are billed at 1-hour granularities. Make sure to use the “Sum” statistic instead of “Average” or else you will be off a lot! My server had values values of around 4,000,000 to 13,000,000 for reads and 5,000,000 to 15,000,000 for writes. These values lined up pretty well to costs per day that I was able to see in Cost Explorer. When Cloudwatch Metrics showed a combined 500M IO’s for a day, I was charged $100. To convert the “Billed IOs” that Aurora reports, you have to divide by the number of seconds in the period. If looking at one-hour period, the 9,000,000 IO’s averages out to 2,500 IOPS (divide by 3600 seconds). 30,000,000 IO’s in an hour equates to an average of 8,333 IOPS.
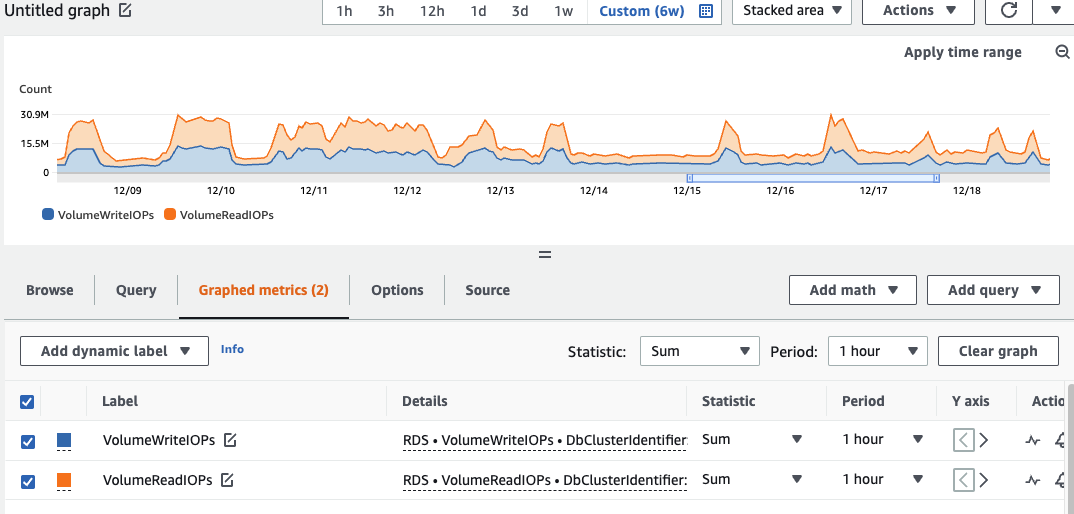
Note that these are averages over an entire hour, so peaks within that hour could be dramatically higher! This gave me confidence that the 12,000 baseline IOPS and availability to pay for up to 64,000 IOPS with GP3 volumes should be able to perform the same workload that was being handled by Aurora.
The effect of Double-Writes
Also, announced in the past month was support for RDS Optimized Writes on newly launched instances within certain instance types. Its unclear if Aurora already has this type of feature enabled, so I’m not certain if the Billed Aurora IO Writes mentioned above would be the number calculated from there, or potentially half of that. Please let me know in comments below if you know, and I’ll update here once I’ve experimented and been able to tell.